Content scraping is a real threat for bloggers and website owners. It is no worse nightmare than discovering that other websites stole your original content or even website design.
Oscar Wilde once said that “imitation is the sincerest form of flattery”– but when someone else copies your website content or design, things can get significantly trickier.
You need to know how to handle it swiftly, effectively, and prudently. Otherwise, your entire website, reputation, or even your business can suffer as a result.
Thus, I decided to write a beginner’s guide on how to manage these issues based on my experience.
Affiliate Disclosure: This post from Victory Tale contains affiliate links. If you subscribe to software products through them, I will receive a small commission from the providers.
Nonetheless, we always value integrity and prioritize our audience’s interests. You can then rest assured that we will present each software truthfully.
1. Don’t Panic
When I first discovered that multiple website pages were copied and posted elsewhere, I admitted that I panicked.
However, panicking is not going to help you go through this mess. You need to stay calm and try not to be excessively emotional. Otherwise, you can make bad decisions and make the issue messier.

Once you stop panicking, you should try to understand their ulterior motives. Below are the top reasons why those thieves steal your content.
1. Negative SEO – Your competitors want to outrank you on search engines. However, they cannot do so in an ethical way, so they hire freelancers or blackhat SEO agencies to use blackhat tactics to pollute your website externally.
They hope that Google or other search engines will realize that your site has duplicate content and lower the search ranking or even deindex your posts, pages, or even an entire site as a result. Hence, their posts can occupy the top spots.
2. Scamming Website Visitors or Destroying your Reputation – Content scrapers might want to scam your website visitors by luring them to a fake site to get their credentials (phishing).
Alternatively, they might pretend to be your official business website and commit misdeeds, thus effectively destroying customer’s trust and your reputation in the process.
3. Income Generation – Your content is well-written and apparently lucrative. Hence, these thieves want to steal your content to generate advertising income or affiliate commissions.
In one of my cases, I discovered that the website owner copied my content just to paste them on his Facebook page to generate income from Facebook instant article ads.
4. Other Mischievous Purposes – Some content scrapers might have many other reasons to copy your content. For example, your competitors in the same industry might be lazy or thrifty to create original content. Thus, they stole your content right away.
2. Search for All Stolen Content
All thieves stealthily copy your content without alerting the original content creators. Thus, it is extremely likely that you never know that someone has already plagiarized your content.
Most bloggers, including me, unexpectedly discover that our content has been stolen. However, if you are looking for a more reliable solution, you can use the tools below to help you find most, if not all, the plagiarized content in minutes.
Also, these tools are highly beneficial if you choose the Kill them All approach (see below)
Copyscape – Copyscape is an uber plagiarism checker with specialized features to help you track down the plagiarism of your content. You can check up to 10000 URLs of your site in a single operation.
Grammarly Premium – The premium Grammarly subscription grants access to its excellent plagiarism checker. You can copy and paste your original content to find out whether other websites copy parts and sections of the article.
Backlink Checkers – If you have added internal links to your posts or pages, content scrapers rarely remove them. Thus, these are still there on the scraper’s website and link back to your posts.
Alternatively, backlink checkers such as Ahrefs, SEMRush, or even Google Search Console will display those links on your profile. You can then investigate the scraper’s site right away.
Tip: If you have hundreds of thousands of backlinks, it can be difficult to track them all. I recommend focusing on the top linking sites first, particularly if such sites are using the same anchor texts.
3. Assess the Damage
Next, you need to conduct thorough research of the case to determine how much content or web design a content thief stole from your site, in other words, determining the “damage” scrapers inflicted on your site.
This step is vital because it will determine how you will treat the issue in later steps. I personally categorize the degree of content scraping into three levels.
Level I: Content scapers steal your content from a single post or page
Level II: Content scrapers steal website content from multiple posts or pages, copy some website design, and hotlink your images. However, you can still easily detect discrepancies between this website and yours.
Level III: Content scrapers create a complete copycat of your site. They stole everything on your website, including your content, web design, and even your website name. The only thing that differentiates their website appearance from yours is the domain name.
Level I and Level II are ugly but far less than level III. If you encounter a level III content scraping, this is when things become dire. You might even need legal assistance to resolve the issue.
4. Select the Right Approach
This step is unarguably the most crucial. You need to select the right strategy to deal with these content scrapers.
There are two strategies that website owners deal with this kind of copyright infringement.
Do Nothing Approach – This approach is practically doing nothing after a thorough incident evaluation (see #4A). It relies on the fact that Google and other search engines have become increasingly smarter in detecting the original creator of the content.
In my opinion, this approach suits the first two levels of content scraping, but definitely not for level III.
Kill them All Approach – The second approach is a direct opposite to the first. You will take action against them.
For example, you might send a cease-and-desist email to those who copied your website content or even send evidence to the scraper’s hosting company to take down the scaper’s entire website.
This approach suits all three levels of content scraping, notably the horrendous level III.
4A. Do Nothing Approach
The Do-Nothing Approach is best for both low levels of content scraping. You will not take any action against content scrapers mainly because it is time-consuming, labor-intensive, or even expensive to do so.
This pacifist approach’s adherents believe it is better to use your time in creating more high-quality articles, particularly if your website is a high-authority one.
However, you need to understand that this approach also has a downside as well. In some increasingly rare cases, scraped content can rank above your original content in search results because Google incorrectly believes the scraper is the original owner of the content.
Furthermore, content scrapers can repost your content on several of their spam websites to pollute your backlink profile (mostly because of negative SEO purposes.)
If you leave them untouched, your website may receive a manual action from Google, and your rankings will tumble in the future.
Hence, even though you choose this approach, you should still perform these tasks to safeguard your website.
First, you need to make sure that content scrapers have not hacked into your website. If you have subscribed to malware removal services, ask a security engineer to investigate your site thoroughly.
Second, you should check the search ranking of that post that is copied whether it remains intact. If scraped content manages to outrank your original content, I suggest you immediately change your approach to Kill them All.
Third, you should check whether those scraped sites are spam sites with poor reputations. Suppose they are. You should use Google’s disavow tool to disavow most or all of them so that they will pollute your backlink profile anymore.
This process may look complicated for new website owners. However, you can use SEMRush’s backlink audit to simplify the process as follows.
You just need to click on the button to start running the audit campaign. This will take a while, but SEMRush will find all the spammy links in your profile.
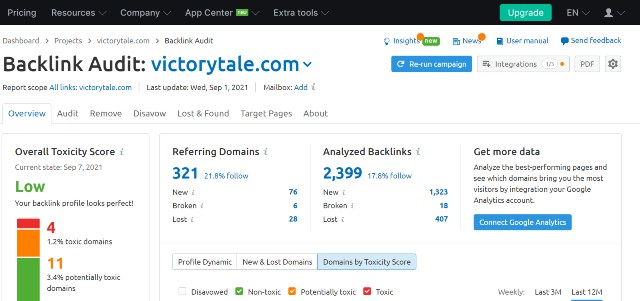
Once you get the results, you can view the toxic domains. If scraper sites are one of them, you can move their domains to a disavow list in one click.
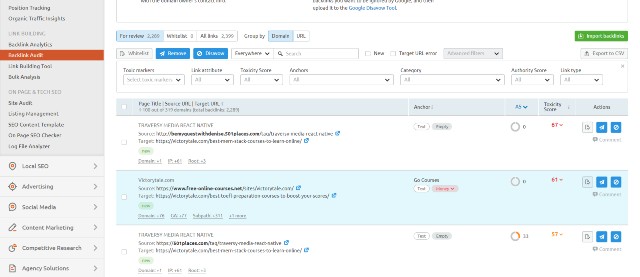
Subsequently, you should open the disavow page on SEMRush and click “Export to TXT.” You will receive the file in the right format that the Google Disavow tool requires.
Finally, just upload it to the Google Disavow tool, and you will be all set!
You can use this SEMRush feature for free after creating a free account. However, you will need a paid account (starting at $99 per month) to view all results.
Fourth: You should disable image hotlinking. Otherwise, content scrapers will use your resources to load website content on their sites.
If you know how to code, you should make changes to your .htaccess file to prevent hotlinking. Alternatively, you can complete the task using Cloudflare Hotlink Protection (free to use).
4B. Kill them All Approach
This approach is straightforward but difficult and troublesome to implement. You will do whatever it takes to get duplicate content removed from the scraper site.
In extreme cases, you might need to send a request to a hosting service to take down the entire website or even start legal action, especially if you encounter level III content scraping.
Despite your immense effort, there is no guarantee that you will be able to remove scraped content. You can spend time and resources to no avail.
If you are determined to continue this approach, below are the steps you want to take to “kill them all.”
Steps to Take
Step 1: First, you will need to collect information about the content scrapers, including their contact information, website information (accessible through whois search), evidence of content scraping (taking screenshots of the copied content would be optimal), social media, etc.
Step 2: Next, contact them through any possible method and ask them to take the scraped content down. You can fill in their contact form or send them messages through social media.
Unfortunately, I have never successfully removed duplicate content this way, and I think many do not as well. Content scrapers never reply to my messages or emails at all. That’s why I moved on to Step 3.
Step 3: Use the information you gather in step 1 to make a request to Google, Facebook, and other tech giants to remove scraped content from showing on their platforms.
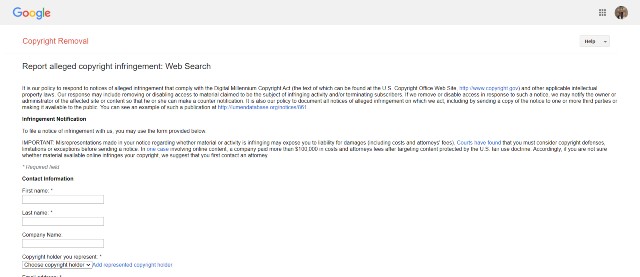
Tip: You should add as many details as possible, especially if the content is not in English. Adding screenshots to their contact forms is also highly recommended.
Based on my experience, I receive responses from both platforms within one business day. However, if you make numerous requests, it could take months until the process is completed.
In my case, Facebook was much faster. A few hours after the support team processed the request, all scraped content disappeared from the scraper’s page.
I was satisfied once I completed step 3 and did not pursue the issue further.
Step 4: If the content scraping is egregious (level III) and you don’t think removing the website from search engines is sufficient, you will need to file a DMCA (Digital Millennium Copyright Act) with content scrapers’ hosting companies.
Alternatively, you can submit a takedown request to domain registrars such as Namecheap or Cloudflare as well.
In doing so, you may need a DMCA takedown notice. You can subscribe to DMCA to swiftly create such notice in minutes. The subscription costs only $10 per month.
Like Step 3, you still need to fill in the contact form. This step certainly takes hours to complete. You should provide as many details as possible, especially the evidence and information that you have gathered.
Once these hosting companies and domain registrars verified your evidence, they will take down the scraped site for you.
Alternatives
The 4-step process I mentioned above is certainly tedious. Fortunately, there is a robust alternative you might want to consider.
DMCA currently offers professional takedown services. Professionals will complete all the tasks for you. Thus, you don’t need to do it on your own.
The service costs $199 per website, which is quite expensive. However, I think the service is worth the price if you have a serious issue with content scraping (i.e., a complex Level III).
Furthermore, suppose DMCA fails to take down the scraped content. You will receive a full refund. Thus, you cannot invest your money to no avail.
5. Safeguard Your Entire Site
Once you have removed the scraped content, you should then adopt preventive measures to safeguard your content. There are some useful tools, tips, and techniques that help you do so.
However, you need to accept that none of these tools or techniques can guarantee that your content will be 100% safe. This will make it much more difficult and tiring for content scrapers to copy your content. Thus, they might choose to give up.
SiteGuarding
SiteGuarding is one of the very few companies that offer reliable website scraping prevention. Below is what you will get from the service.

Bot Prevention: SiteGuarding will block all suspicious bots that aim to scrape your content. It will also protect your website from hacker attacks.
Browser ID Protection – SiteGuarding adds a layer of defense to your website by blocking bots and scrapers using the browser ID. Thus, they can’t evade the protection by using proxy servers and VPNs.
Text to SVG – This uber protection adds the foremost protection layer to your content. SiteGuarding will convert parts of the text on your site to SVG images. Hence, scrapers can’t copy your content to paste it on their site.
Bots and content scrapers will only get useless image codes, while regular users can view them as normal.
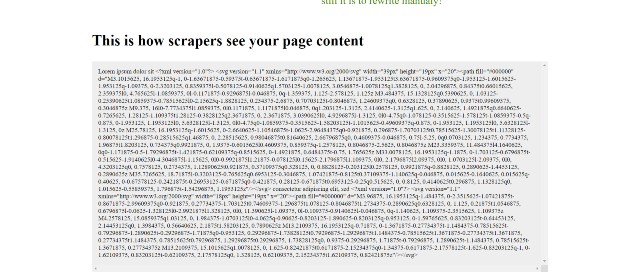
Content Usage Monitoring – SiteGuarding will automatically monitor the usage of your content. If evidence of content scraping flares up, it will notify you and Siteguarding’s team immediately.
Once notified, the team will submit takedown requests (both to Google and the hosting company on your behalf.)
SiteGuarding’s pricing starts at 35 EUR ($41.5) per month for protecting 50 pages on your site. If you want SiteGuarding to protect all other pages, you need to upgrade to higher plans.
In my opinion, the service fees are expensive. Nonetheless, if someone copies your content regularly, it will be out of the question to track and remove all the scraped content.
At that point, DMCA professional takedowns would also become unaffordable. Thus, protecting your hard work and reputation with SiteGuarding may be the last resort.
DMCA Badges
You can add DMCA badges to each of your website posts or pages. Once you correctly install the badge, DMCA will create a digital signature for that post or page by taking a snapshot of the source code and encrypting it.
If content thieves steal your content with a badge after 30 days of installation, DMCA will take down the scraped content for free.
This service costs only $10 per month. I think it is an excellent investment to safeguard your content.
WordProof
WordProof is a great tool that aims to protect websites from content scraping. Utilizing blockchain technology, WordProof creates an unalterable timestamp for your content. This timestamp is solid evidence that you are the original creator of the content.
If you are interested, you can purchase a lifetime deal through Appsumo, costing only $99 per month.
6. Additional Tips
Below are some other tips and techniques that you can implement to protect your content or at least gain some benefits from scraped content.
Internal links
Internal links will not protect your content at all. However, once the scraper posts your content on their site. All the links embedded there will function as backlinks that direct visitors back to your site.
However, creating internal links on a large site can be time-consuming. I suggest using InLinks to do so. The platform comes with a smart internal link builder and a top-notch content optimization tool.
Note: Keep in mind that if a scraper site is one of the spam sites, it may be better to disavow those links (as mentioned above).
Alerts
You can use these tools to add alerts to your website. You will be notified immediately if someone has just copied your content.
Trackbacks – WordPress users will get a trackback notification every time external sites link to them. Thus, if someone copies your content, you will be notified instantly. However, most bloggers seem to ignore or even disable trackbacks because they can be annoying.
Google Alerts – You can set up an alert using this tool. If content scrapers publish the same content using the same title, you will be notified right away.
Technical Adjustments
You can make several adjustments to your site to make it tougher. However, all adjustments require web development knowledge. If you don’t know how to code, it is risky to implement such changes as they can break your site.
RSS Feed – Many content scrapers use the RSS feed to steal your content. You can change the settings to show only the summary or disable it altogether (several WordPress plugins can do the job).
Bot Protection – You can create honey-pot pages, use CAPTCHAs, or use rate-limiting to block suspicious requests from scraping bots.